iOS - ECC椭圆曲线、ECDSA签名验签和ECIES加解密
前言
ECC英文全称"Ellipse Curve Cryptography",与传统的基于大质数因子分解困难性的加密方法不同,ECC通过椭圆曲线方程式的性质产生密钥
ECC164位的密钥产生一个安全级,相当于RSA 1024位密钥提供的保密强度,而且计算量较小,处理速度更快,存储空间和传输带宽占用较少。目前我国居民二代身份证正在使用 256 位的椭圆曲线密码,虚拟货币比特币也选择ECC作为加密算法。
加密
基于这个秘密值,用来对Alice和Bob之间的报文进行加密的实际方法是适应以前的,最初是在其他组中描述使用的离散对数密码系统。这些系统包括:
Diffie-Hellman—ECDH
MQV—ECMQV
ElGamal discrete log cryptosystem—ECElGamal
数字签名算法—ECDSA
对于ECC系统来说,完成运行系统所必须的群操作比同样大小的因数分解系统或模整数离散对数系统要慢。不过,ECC系统的拥护者相信ECDLP问题比DLP或因数分解问题要难的多,并且因此使用ECC能用小的多的密钥长度来提供同等的安全,在这方面来说它确实比例如RSA之类的更快。到目前为止已经公布的结果趋于支持这个结论,不过一些专家表示怀疑。
ECC被广泛认为是在给定密钥长度的情况下,最强大的非对称算法,因此在对带宽要求十分紧的连接中会十分有用。
优点
安全性高
有研究表示160位的椭圆密钥与1024位的RSA密钥安全性相同。
处理速度快
在私钥的加密解密速度上,ecc算法比RSA、DSA速度更快。
存储空间占用小。
带宽要求低。
以上为ECC椭圆曲线算法需要了解的基本知识,摘自强大的百科度娘。
iOS-ECC
关于ECC,苹果支持以下算法:
PKG:
curves P-224, P-256, P-384, P-521
PKV:
curves P-224, P-256, P-384, P-521
Signature Generation:
curves P-224, P-256, P-384, P-521
using (SHA-224, SHA-256, SHA384, SHA512)
Signature Verification:
curves P-224, P-256, P-384, P-521
using (SHA-1, SHA-224, SHA-256, SHA384, SHA512)
采用的都是NIST标准和规范。但是苹果官方API仅为开发者提供了椭圆曲线P-256的256位EC密钥。由于苹果SEP硬件提供的保护机制,私钥会直接以keychain的形式截留在SEP中,不能提取,也不能从外部导入,只能通过引用使用。
ECDSA
椭圆曲线数字签名算法(ECDSA)是使用椭圆曲线密码(ECC)对数字签名算法(DSA)的模拟,下面是关于ECDSA的API调用。
1、创建ECC椭圆曲线的keychain属性,属性设置具体可以根据自己需要,获取ECC私钥。
sacObject = SecAccessControlCreateWithFlags(kCFAllocatorDefault,
kSecAttrAccessibleWhenPasscodeSetThisDeviceOnly,
// kSecAccessControlTouchIDAny |
kSecAccessControlPrivateKeyUsage, &error);
// Create parameters dictionary for key generation.
NSDictionary *parameters = @{
(id)kSecAttrTokenID: (id)kSecAttrTokenIDSecureEnclave,
(id)kSecAttrKeyType: (id)kSecAttrKeyTypeECSECPrimeRandom,
(id)kSecAttrKeySizeInBits: @256,
(id)kSecAttrLabel: @"my-se-key",
(id)kSecPrivateKeyAttrs: @{
(id)kSecAttrAccessControl: (__bridge_transfer id)sacObject,
(id)kSecAttrIsPermanent: @YES,
}
};
NSError *gen_error = nil;
//根据参数生成私钥
id privateKey = CFBridgingRelease(SecKeyCreateRandomKey((__bridge CFDictionaryRef)parameters, (voidvoid *)&gen_error));
2.使用私钥提取公钥,并用于签名。
//根据keychain的属性查找ECC私钥,并获取私钥引用。
NSDictionary *params = @{
(id)kSecClass: (id)kSecClassKey, (id)kSecAttrKeyType: (id)kSecAttrKeyTypeECSECPrimeRandom, (id)kSecAttrKeySizeInBits: @256, (id)kSecAttrLabel: @"my-se-key", (id)kSecReturnRef: @YES, (id)kSecUseOperationPrompt: @"Authenticate to sign data" };
SecKeyRef privateKey;
OSStatus status = SecItemCopyMatching((__bridge CFDictionaryRef)params, (CFTypeRef *)&privateKey);
3.签名
NSError *error;
NSData *dataToSign = [@"我是签名内容" dataUsingEncoding:NSUTF8StringEncoding];
NSData *signature = CFBridgingRelease(SecKeyCreateSignature(privateKey, kSecKeyAlgorithmECDSASignatureMessageX962SHA256, (CFDataRef)dataToSign, (voidvoid *)&error));
对于kSecKeyAlgorithmECDSASignatureMessageX962SHA256签名算法,官方还给了:SHA1、SHA224、SHA384、SHA512用于EC密钥摘要。可以自己需求选择签名对应的摘要算法。API的名字也很明确的给了这里执行的标准规范为X9.62。
4.验签
//提取公钥,进行验签,验签选择的算法必须与签名时的算法一致。
id publicKey = CFBridgingRelease(SecKeyCopyPublicKey((SecKeyRef)privateKey));
Boolean verified = SecKeyVerifySignature((SecKeyRef)publicKey, kSecKeyAlgorithmECDSASignatureMessageX962SHA256, (CFDataRef)dataToSign, (CFDataRef)signature, (void *)&error); if (verified == 1) { message = [NSString stringWithFormat:@"signature:%@ verified:%@ error:%@", signature, @"验签成功", error]; }else{ message = [NSString stringWithFormat:@"signature:%@ verified:%@ error:%@", signature, @"验签失败", error]; }
##ECIES
校验密钥是否和算法是否匹配,只有都符合条件了才能用于加密。
SecKeyAlgorithm algorithm = kSecKeyAlgorithmECIESEncryptionCofactorX963SHA256AESGCM;
BOOL canEncrypt = SecKeyIsAlgorithmSupported((SecKeyRef)publicKey,kSecKeyOperationTypeEncrypt, algorithm);
加密
CFErrorRef error = NULL;
cipherText = (NSData*)CFBridgingRelease( // ARC takes ownership
SecKeyCreateEncryptedData(publicKey,
algorithm,
(__bridge CFDataRef)encryptionData,&error));
encryptionData为要加密的数据,这里提示一下:
As an additional check before encrypting, because asymmetric encryption restricts the length of the data that you can encrypt, verify that the data is short enough. For this particular algorithm, the plain text data must be 130 bytes smaller than the key’s block size, as reported by SecKeyGetBlockSize. You therefore further condition the proceedings on a length test:
NSData* plainText = ;
canEncrypt &= ([plainText length] < (SecKeyGetBlockSize(publicKey)-130));
官方API描述,明文数据要比密钥块小130个字节。
解密
CFErrorRef error = NULL;
clearText = (NSData*)CFBridgingRelease( // ARC takes ownership
SecKeyCreateDecryptedData(private,
algorithm,
(__bridge CFDataRef)cipherText,
https://developer.virgilsecurity.com/docs/sdk-and-tools
https://kjur.github.io/jsrsasign/sample/sample-ecdsa.html
https://forums.developer.apple.com/thread/87758
PUBLIC_KEY = "MFYwEAYHKoZIzj0CAQYFK4EEAAoDQgAESJCvH4lEoGgLof637UGdAYHwFW0GddD/DbVu8yFVTt5Zq+kkftDpQDelSnhmmbr9v+ZsIESINctknP3LTbeLIg==";
PRIVATE_KEY = "MIGNAgEAMBAGByqGSM49AgEGBSuBBAAKBHYwdAIBAQQgi5h75Y80gEeJQQZ6zq7zjT9a11lyLhf9kF/ItIGFDHCgBwYFK4EEAAqhRANCAARIkK8fiUSgaAuh/rftQZ0BgfAVbQZ10P8NtW7zIVVO3lmr6SR+0OlAN6VKeGaZuv2/5mwgRIg1y2Sc/ctNt4si";
Pyhton3一则下载代码
from urllib.request import urlretrieve
import os
def download(url, savepath='./'):
"""
download file from internet
:param url: path to download from
:param savepath: path to save files
:return: None
"""
def reporthook(a, b, c):
"""
显示下载进度
:param a: 已经下载的数据块
:param b: 数据块的大小
:param c: 远程文件大小
:return: None
"""
print("\rdownloading: %5.1f%%" % (a * b * 100.0 / c), end="")
filename = os.path.basename(url)
# 判断文件是否存在,如果不存在则下载
if not os.path.isfile(os.path.join(savepath, filename)):
print('Downloading data from %s' % url)
urlretrieve(url, os.path.join(savepath, filename), reporthook=reporthook)
print('\nDownload finished!')
else:
print('File already exsits!')
# 获取文件大小
filesize = os.path.getsize(os.path.join(savepath, filename))
# 文件大小默认以Bytes计, 转换为Mb
print('File size = %.2f Mb' % (filesize/1024/1024))
if name == 'main':
# 以下载cifar-10数据集为例
url = "https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz"
download(url, savepath='./')
Python中关于“warning: Debugger speedups using cython not found”问题的解决
问题描述:Cython加速调试没有打开。Cython是Python的一个扩展模块工具,采用Python和C语言混合编成,用于加速Python计算速度。
解决方法:
- 打开终端:找到“Pycharm/pycharm-community-2016.2.2/helpers/pydev”完整路径,然后cd到那里,比如我的是:“cd madd/soft/Pycharm/pycharm-community-2016.2.2/helpers/pydev”;
- 输入:“python setup_cython.py build_ext --inplace”,回车;再次运行程序,发现warning已经没有了。
参考:https://blog.jetbrains.com/pycharm/2016/02/faster-debugger-in-pycharm-5-1/
Scrapy爬虫使用
From:https://www.cnblogs.com/wanghzh/p/5824181.html
Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
Scratch,是抓取的意思,这个Python的爬虫框架叫Scrapy,大概也是这个意思吧,就叫它:小刮刮吧。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下:
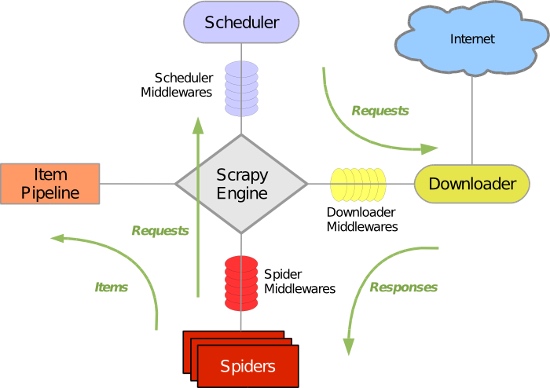
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
##基本使用
-
创建项目
运行命令:scrapy startproject p1(your_project_name) -
自动创建目录的结果:
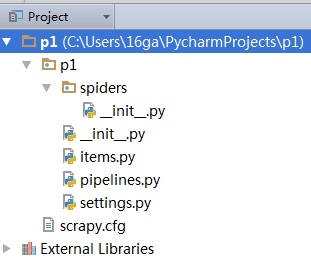
文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
- 编写爬虫
在spiders目录中新建 xiaohuar_spider.py 文件
示例代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy
class XiaoHuarSpider(scrapy.spiders.Spider):
name = "xiaohuar"
allowed_domains = ["xiaohuar.com"]
start_urls = [
"http://www.xiaohuar.com/hua/",
]
def parse(self, response):
# print(response, type(response))
# from scrapy.http.response.html import HtmlResponse
# print(response.body_as_unicode())
current_url = response.url #爬取时请求的url
body = response.body #返回的html
unicode_body = response.body_as_unicode()#返回的html unicode编码
备注:
1.爬虫文件需要定义一个类,并继承scrapy.spiders.Spider
2.必须定义name,即爬虫名,如果没有name,会报错。因为源码中是这样定义的:
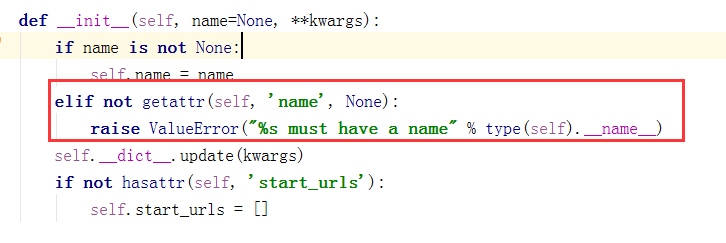
3.编写函数parse,这里需要注意的是,该函数名不能改变,因为Scrapy源码中默认callback函数的函数名就是parse;
4.定义需要爬取的url,放在列表中,因为可以爬取多个url,Scrapy源码是一个For循环,从上到下爬取这些url,使用生成器迭代将url发送给下载器下载url的html。源码截图:


4、运行
进入p1目录,运行命令
scrapy crawl xiaohau --nolog
格式:scrapy crawl+爬虫名 --nolog即不显示日志
5.scrapy查询语法:
当我们爬取大量的网页,如果自己写正则匹配,会很麻烦,也很浪费时间,令人欣慰的是,scrapy内部支持更简单的查询语法,帮助我们去html中查询我们需要的标签和标签内容以及标签属性。下面逐一进行介绍:
- 查询子子孙孙中的某个标签(以div标签为例)://div
- 查询儿子中的某个标签(以div标签为例):/div
- 查询标签中带有某个class属性的标签://div[@class='c1']即子子孙孙中标签是div且class=‘c1’的标签
- 查询标签中带有某个class=‘c1’并且自定义属性name=‘alex’的标签://div[@class='c1'][@name='alex']
- 查询某个标签的文本内容://div/span/text() 即查询子子孙孙中div下面的span标签中的文本内容
- 查询某个属性的值(例如查询a标签的href属性)://a/@href
示例代码
def parse(self, response):
# 分析页面
# 找到页面中符合规则的内容(校花图片),保存
# 找到所有的a标签,再访问其他a标签,一层一层的搞下去
hxs = HtmlXPathSelector(response)#创建查询对象
# 如果url是 http://www.xiaohuar.com/list-1-\d+.html
if re.match('http://www.xiaohuar.com/list-1-\d+.html', response.url): #如果url能够匹配到需要爬取的url,即本站url
items = hxs.select('//div[@class="item_list infinite_scroll"]/div') #select中填写查询目标,按scrapy查询语法书写
for i in range(len(items)):
src = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/a/img/@src' % i).extract()#查询所有img标签的src属性,即获取校花图片地址
name = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/span/text()' % i).extract() #获取span的文本内容,即校花姓名
school = hxs.select('//div[@class="item_list infinite_scroll"]/div[%d]//div[@class="img"]/div[@class="btns"]/a/text()' % i).extract() #校花学校
if src:
ab_src = "http://www.xiaohuar.com" + src[0]#相对路径拼接
file_name = "%s_%s.jpg" % (school[0].encode('utf-8'), name[0].encode('utf-8')) #文件名,因为python27默认编码格式是unicode编码,因此我们需要编码成utf-8
file_path = os.path.join("/Users/wupeiqi/PycharmProjects/beauty/pic", file_name)
urllib.urlretrieve(ab_src, file_path)
注:urllib.urlretrieve(ab_src, file_path) ,接收文件路径和需要保存的路径,会自动去文件路径下载并保存到我们指定的本地路径。
5.递归爬取网页
上述代码仅仅实现了一个url的爬取,如果该url的爬取的内容中包含了其他url,而我们也想对其进行爬取,那么如何实现递归爬取网页呢?
示例代码:
# 获取所有的url,继续访问,并在其中寻找相同的url
all_urls = hxs.select('//a/@href').extract()
for url in all_urls:
if url.startswith('http://www.xiaohuar.com/list-1-'):
yield Request(url, callback=self.parse)
即通过yield生成器向每一个url发送request请求,并执行返回函数parse,从而递归获取校花图片和校花姓名学校等信息。
注:可以修改settings.py 中的配置文件,以此来指定“递归”的层数,如: DEPTH_LIMIT = 1
6.scrapy查询语法中的正则:
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
html = """<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<li class="item-"><a href="link.html">first item</a></li>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
</body>
</html>
"""
response = HtmlResponse(url='http://example.com', body=html,encoding='utf-8')
ret = Selector(response=response).xpath('//li[re:test(@class, "item-\d*")]//@href').extract()
print(ret)
语法规则:Selector(response=response查询对象).xpath('//li[re:test(@class, "item-\d*")]//@href').extract(),即根据re正则匹配,test即匹配,属性名是class,匹配的正则表达式是"item-\d*",然后获取该标签的href属性。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy
import hashlib
from tutorial.items import JinLuoSiItem
from scrapy.http import Request
from scrapy.selector import HtmlXPathSelector
class JinLuoSiSpider(scrapy.spiders.Spider):
count = 0
url_set = set()
name = "jluosi"
domain = 'http://www.jluosi.com'
allowed_domains = ["jluosi.com"]
start_urls = [
"http://www.jluosi.com:80/ec/goodsDetail.action?jls=QjRDNEIzMzAzOEZFNEE3NQ==",
]
def parse(self, response):
md5_obj = hashlib.md5()
md5_obj.update(response.url)
md5_url = md5_obj.hexdigest()
if md5_url in JinLuoSiSpider.url_set:
pass
else:
JinLuoSiSpider.url_set.add(md5_url)
hxs = HtmlXPathSelector(response)
if response.url.startswith('http://www.jluosi.com:80/ec/goodsDetail.action'):
item = JinLuoSiItem()
item['company'] = hxs.select('//div[@class="ShopAddress"]/ul/li[1]/text()').extract()
item['link'] = hxs.select('//div[@class="ShopAddress"]/ul/li[2]/text()').extract()
item['qq'] = hxs.select('//div[@class="ShopAddress"]//a/@href').re('.*uin=(?P<qq>\d*)&')
item['address'] = hxs.select('//div[@class="ShopAddress"]/ul/li[4]/text()').extract()
item['title'] = hxs.select('//h1[@class="goodsDetail_goodsName"]/text()').extract()
item['unit'] = hxs.select('//table[@class="R_WebDetail_content_tab"]//tr[1]//td[3]/text()').extract()
product_list = []
product_tr = hxs.select('//table[@class="R_WebDetail_content_tab"]//tr')
for i in range(2,len(product_tr)):
temp = {
'standard':hxs.select('//table[@class="R_WebDetail_content_tab"]//tr[%d]//td[2]/text()' %i).extract()[0].strip(),
'price':hxs.select('//table[@class="R_WebDetail_content_tab"]//tr[%d]//td[3]/text()' %i).extract()[0].strip(),
}
product_list.append(temp)
item['product_list'] = product_list
yield item
current_page_urls = hxs.select('//a/@href').extract()
for i in range(len(current_page_urls)):
url = current_page_urls[i]
if url.startswith('http://www.jluosi.com'):
url_ab = url
yield Request(url_ab, callback=self.parse)
响应cookie:
def parse(self, response):
from scrapy.http.cookies import CookieJar
cookieJar = CookieJar()
cookieJar.extract_cookies(response, response.request)
print(cookieJar._cookies)
更多选择器规则:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/selectors.html
7、格式化处理
上述实例只是简单的图片处理,所以在parse方法中直接处理。如果对于想要获取更多的数据(获取页面的价格、商品名称、QQ等),则可以利用Scrapy的items将数据格式化,然后统一交由pipelines来处理。即不同功能用不同文件实现。
items:即用户需要爬取哪些数据,是用来格式化数据,并告诉pipelines哪些数据需要保存。
示例items.py文件:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class JieYiCaiItem(scrapy.Item):
company = scrapy.Field()
title = scrapy.Field()
qq = scrapy.Field()
info = scrapy.Field()
more = scrapy.Field()
即:需要爬取所有url中的公司名,title,qq,基本信息info,更多信息more。
上述定义模板,以后对于从请求的源码中获取的数据同样按照此结构来获取,所以在spider中需要有一下操作:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy
import hashlib
from beauty.items import JieYiCaiItem
from scrapy.http import Request
from scrapy.selector import HtmlXPathSelector
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class JieYiCaiSpider(scrapy.spiders.Spider):
count = 0
url_set = set()
name = "jieyicai"
domain = 'http://www.jieyicai.com'
allowed_domains = ["jieyicai.com"]
start_urls = [
"http://www.jieyicai.com",
]
rules = [
#下面是符合规则的网址,但是不抓取内容,只是提取该页的链接(这里网址是虚构的,实际使用时请替换)
#Rule(SgmlLinkExtractor(allow=(r'http://test_url/test?page_index=\d+'))),
#下面是符合规则的网址,提取内容,(这里网址是虚构的,实际使用时请替换)
#Rule(LinkExtractor(allow=(r'http://www.jieyicai.com/Product/Detail.aspx?pid=\d+')), callback="parse"),
]
def parse(self, response):
md5_obj = hashlib.md5()
md5_obj.update(response.url)
md5_url = md5_obj.hexdigest()
if md5_url in JieYiCaiSpider.url_set:
pass
else:
JieYiCaiSpider.url_set.add(md5_url)
hxs = HtmlXPathSelector(response)
if response.url.startswith('http://www.jieyicai.com/Product/Detail.aspx'):
item = JieYiCaiItem()
item['company'] = hxs.select('//span[@class="username g-fs-14"]/text()').extract()
item['qq'] = hxs.select('//span[@class="g-left bor1qq"]/a/@href').re('.*uin=(?P<qq>\d*)&')
item['info'] = hxs.select('//div[@class="padd20 bor1 comard"]/text()').extract()
item['more'] = hxs.select('//li[@class="style4"]/a/@href').extract()
item['title'] = hxs.select('//div[@class="g-left prodetail-text"]/h2/text()').extract()
yield item
current_page_urls = hxs.select('//a/@href').extract()
for i in range(len(current_page_urls)):
url = current_page_urls[i]
if url.startswith('/'):
url_ab = JieYiCaiSpider.domain + url
yield Request(url_ab, callback=self.parse)
上述代码中:对url进行md5加密的目的是避免url过长,也方便保存在缓存或数据库中。
此处代码的关键在于:
将获取的数据封装在了Item对象中
yield Item对象 (一旦parse中执行yield Item对象,则自动将该对象交个pipelines的类来处理)
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
from twisted.enterprise import adbapi
import MySQLdb.cursors
import re
mobile_re = re.compile(r'(13[0-9]|15[012356789]|17[678]|18[0-9]|14[57])[0-9]{8}')
phone_re = re.compile(r'(\d+-\d+|\d+)')
class JsonPipeline(object):
def __init__(self):
self.file = open('/Users/wupeiqi/PycharmProjects/beauty/beauty/jieyicai.json', 'wb')
def process_item(self, item, spider):
line = "%s %s\n" % (item['company'][0].encode('utf-8'), item['title'][0].encode('utf-8'))
self.file.write(line)
return item
class DBPipeline(object):
def __init__(self):
self.db_pool = adbapi.ConnectionPool('MySQLdb',
db='DbCenter',
user='root',
passwd='123',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True)
def process_item(self, item, spider):
query = self.db_pool.runInteraction(self._conditional_insert, item)
query.addErrback(self.handle_error)
return item
def _conditional_insert(self, tx, item):
tx.execute("select nid from company where company = %s", (item['company'][0], ))
result = tx.fetchone()
if result:
pass
else:
phone_obj = phone_re.search(item['info'][0].strip())
phone = phone_obj.group() if phone_obj else ' '
mobile_obj = mobile_re.search(item['info'][1].strip())
mobile = mobile_obj.group() if mobile_obj else ' '
values = (
item['company'][0],
item['qq'][0],
phone,
mobile,
item['info'][2].strip(),
item['more'][0])
tx.execute("insert into company(company,qq,phone,mobile,address,more) values(%s,%s,%s,%s,%s,%s)", values)
def handle_error(self, e):
print 'error',e
上述代码中多个类的目的是,可以同时保存在文件和数据库中,保存的优先级可以在配置文件settings中定义。
ITEM_PIPELINES = {
'beauty.pipelines.DBPipeline': 300,
'beauty.pipelines.JsonPipeline': 100,
}
# 每行后面的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。
iOS 中的 Promise 设计模式
做iOS开发的同学都非常熟悉代理模式,为避免代码耦合,代理模式的委托者任务交给代理执行,代理执行完毕之后再把回调告诉委托者。委托者不关心代理是怎么执行任务的,只关心结果是成功还是失败。代理模式就像是杀手与雇主的关系一样。
但是代理模式也不完美,代理多了,雇主也管不过来了,委托在A处,收结果却要在B处。有的时候,雇主也希望能在同一个地方既可以发配任务,也可以接收结果。闭包Block就能帮雇主解决这个问题了。无论是系统的GCD,还是平时随手封装一个 UIAlertView 的block实现,都让代码的可读性有了一定的提升。
无论是代理模式,还是闭包,在处理单一任务的时候,都出色的完成了任务。可是当两种模式要相互配合,一起完成一系列任务,并且每个任务之间还要共享信息,相互衔接,雇主就要头疼了。当然可以只用一种模式来实现,代理模式就不说了,过于分散,不善于处理这种流程性的事务。那我用闭包来举一个例子:我们需要顺序执行Task A、B、C 三个任务,A、B、C依次执行,任务完成之后都使用闭包来回调并开始下一个任务。代码如下:
- (void)callbackHell
{
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[self doTaskA:^{
[self doTaskB:^{
[self doTaskC:^{
// all task done
}];
}];
}];
});
}
上面的代码看起来挺清晰,可读性也还可。如果加上一些 ifelse 的分支判断,再加上一些参数的传递,代码不知不觉的向右延伸,最终超出了屏幕的宽度,形成一个倒金字塔的形状。写 JavaScript 的同学会说:你已经掉进了回调陷阱(CallbackHell),赶紧用Promise设计模式来跳坑吧。
##Promise 设计模式的原理
Promise设计模式把每一个异步操作都封装成一个Promise对象,这个Promise对象就是这个异步操作执行完毕的结果,但是这个结果是可变的,就像薛定谔的猫,只有执行了才知道。通过这种方式,就能提前获取到结果,并处理下一步骤。
Promise 使用 then 作为关键字,回调最终结果。 then 是整个Promise设计模式的核心,必须要被实现。另外还有其它几个关键字用来表示一个Promise对象的状态:
-
pending: 任务执行中,状态可能会进入下面的fullfill或者reject二者之一
-
fufill/resolved: 任务完成了,返回结果
-
reject: 任务失败,并返回错误更多可以参考 官方规范。
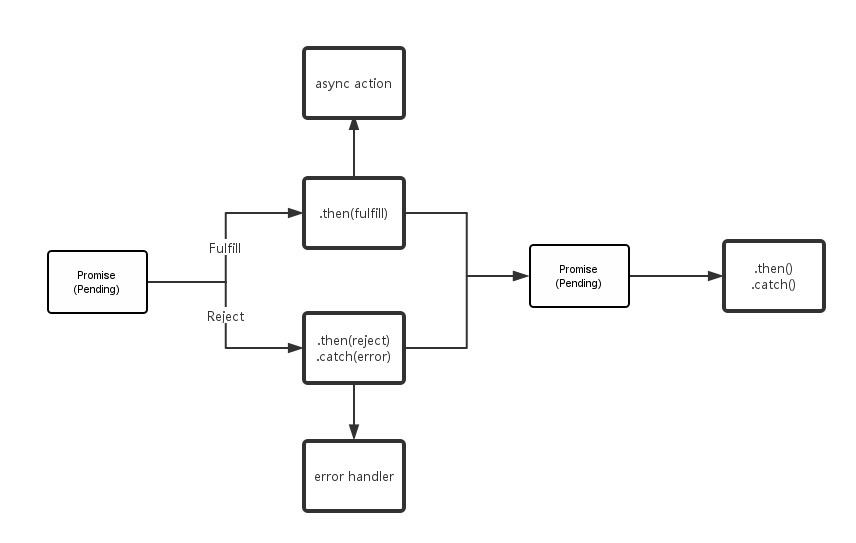
如上图所示,fullfill与reject的状态都是不可逆转的,保证了结果的唯一性。除了 then ,一些对 Promise 的实现还有几个关键字用来扩展,让代码可读性更强:
-
catch: 任务失败,处理error
-
finally: 无论是遇到 then 还是 catch 分支,最终都会执行的回调
-
when: 多个异步任务执行完毕之后才会回调
##Promise模式的实现
Promise设计模式在 iOS/MacOS 平台的最佳实践是由大名鼎鼎的homebrew的作者 Max Howell 写的一个支持iOS/MacOS 的异步编程框架 – PromiseKit , 作者的另一个广为人知的趣事是因为没有写出反转二叉树而没有拿到Google的offer。
我们先抛出对上面改良函数使用PromiseKit的实现,再看原理:
- (void)jumpOutCallbackHell
{
[self promiseTaskA].then(^{
return [self promiseTaskB];
}).then(^{
return [self promiseTaskC];
}).then(^{
NSLog(@"all task done");
});
}
调试后,发现执行的结果与我们期待的一致,但是上面的代码对我来说有几个疑惑点:
then 是怎么串起来的;
怎么实现的顺序调用;
如果传递参数,参数是怎么传递的。
带着问题,来看Promise的源码:
- (PMKPromise *(^)(id))then {
return ^(id block){
return self.thenOn(dispatch_get_main_queue(), block);
};
}
如果对block不是很熟悉,可能不太理解这段代码,实际上,PromiseKit灵活的使用了block作为函数的返回值来实现链式调用。相比原来的block嵌套模式,PromiseKit使用block将多个 then 串联起来,解决了callback hell。
接着来继续看下一个问题。
- (id)resolved:(PMKResolveOnQueueBlock(^)(id result))mkresolvedCallback
pending:(void(^)(id result, PMKPromise *next, dispatch_queue_t q, id block, void (^resolver)(id)))mkpendingCallback
{
__block PMKResolveOnQueueBlock callBlock;
__block id result;
dispatch_sync(_promiseQueue, ^{
if ((result = _result))
return;
callBlock = ^(dispatch_queue_t q, id block) {
block = [block copy];
__block PMKPromise *next = nil;
dispatch_barrier_sync(_promiseQueue, ^{
if ((result = _result))
return;
__block PMKPromiseFulfiller resolver;
next = [PMKPromise new:^(PMKPromiseFulfiller fulfill, PMKPromiseRejecter reject) {
resolver = ^(id o){
if (IsError(o)) reject(o); else fulfill(o);
};
}];
[_handlers addObject:^(id value){
mkpendingCallback(value, next, q, block, resolver);
}];
});
return next ?: mkresolvedCallback(result)(q, block);
};
});
return callBlock ?: mkresolvedCallback(result);
}
代码有点长,不过也可以理解。这个方法是上面的thenon调用的,接受两个参数,第一个参数是一个resolve的block,第二个参数是一个pending的block。一个Promise在执行完毕之后,无论状态是变成resolve还是pending,都通过这个方法,执行对应的 then,并返回一个Promise对象。上面的函数中,有一个dispatch_barrier_sync ,barrier是栅栏的意思,一般来说如果我们有多个异步任务,但是希望他们按照一定的顺序执行,就可以使用这个方法。在这里PromiseKit通过barrier实现了then的依次调用。在这个barrier方法内部,一个是会去看当前是否已经有下一个要执行的Promise,如果没有就生成一个新的,另一个把对应的pending 放到handler队列,依次执行。
##参数传递
这里需要思考的另外一个问题是,既然多个任务之间有依次调用的关系,那么这样的一种任务流之间如何互相通信呢?PromiseKit用了一个比较有趣的办法来实现相邻Promise对象的参数传递。
在万物皆消息的OC语言内部,每一个方法,包括Block在内都是有类型签名的。这个类型签名对象就是 NSMethodSignature
@interface NSMethodSignature : NSObject {
...
@property (readonly) NSUInteger numberOfArguments;
...
@property (readonly) const char *methodReturnType NS_RETURNS_INNER_POINTER;
...
@end
那么对于block,怎么获取类型签名呢?PromiseKit自己定义了一个block的结构体:
struct PMKBlockLiteral {
void *isa;
int flags;
int reserved;
void (*invoke)(void *, ...);
struct block_descriptor {
unsigned long int reserved; // NULL
unsigned long int size; // sizeof(struct Block_literal_1)
void (*copy_helper)(void *dst, void *src); // IFF (1<<25)
void (*dispose_helper)(void *src); // IFF (1<<25)
const char *signature; // IFF (1<<30)
} *descriptor;
};
熟悉block的同学都知道,flags按照bit位保存了一些block的附加信息,在 1<<30的这个bit可以找到是否有类型签名signature,剩下的就是通过flags移动指针,找到signature所在的内存空间了。找到了signature,也就获取到了参数个数与函数返回值这些信息。函数返回值的类型是经过编码的,具体的对照表可以参考官方文档
id pmk_safely_call_block(id frock, id result) {
NSMethodSignature *sig = NSMethodSignatureForBlock(frock);
const NSUInteger nargs = sig.numberOfArguments;
const char rtype = sig.methodReturnType[0];
type (^block)(id, id, id) = frock;
return [result class] == [PMKArray class]
? block(result[0], result[1], result[2])
: block(result, nil, nil);
}
有了函数签名,就能知道block的信息了。上面只截取了部分代码,简单来说,PromiseKit 通过动态的获取block的参数个数与返回类型来决定block的调用。一般来说, fullfill(id) 在调用的时候最多只支持传递一个参数,在必要的时候,PromiseKit把这些参数放在一个数组里面,这个数组就是 PMKArray ,当检测到这个参数是一个数组的时候,就依次取出数组内的元素作为参数传递。
从而支持了多个参数的传递。
##总结
至此, 对PromiseKit的一些解释也就结束了,PromiseKit有OC的1.0版本,也有支持了swift的3.0版本。如果你非常享受这样的书写方式,可以接入很多扩展的版本,可以写出看起来优雅又舒服的代码,比如 NSURLSession :
URLSession.GET("http://example.com").asDictionary().then { json in
}.catch { error in
//…
}
还有很多的扩展与关键字的支持,这里都不再展开。
而对于我来说,Promise设计模式能够解决我对散落在各处的代理模式产生的代码的烦恼,也让我避免了跳进回调陷阱,就值得总结了。
FROM:iOS 中的 Promise 设计模式
Copyright © 2015 Powered by MWeb, 豫ICP备09002885号-5